
基于車道線寬度的邊緣散點識別道線算法
為了解決這兩個問題,需要將攝像頭采集的原始圖像中的ROI區域轉化為鳥瞰圖,然后通過基于車道線寬度的特征點篩選方法提取車道線的邊緣點,最后得到車道線的邊緣點。
1、車道線特征點的選擇與提取
該方法利用了車道寬度基本相同的特點,一般的鳥瞰圖中寬度為0.25米的車道線寬度為4~5個像素,且車道線內部是一個連通的區域。將相機采集的圖像轉化為鳥瞰圖后,采用Canny算法進行處理,初步得到包含邊緣點和噪聲點的二值圖像。然后,通過逐行掃描的方法對二值圖像進行濾波,提取屬于車道線的邊緣點,丟棄其余點,以減少干擾噪聲點對曲線擬合的影響。
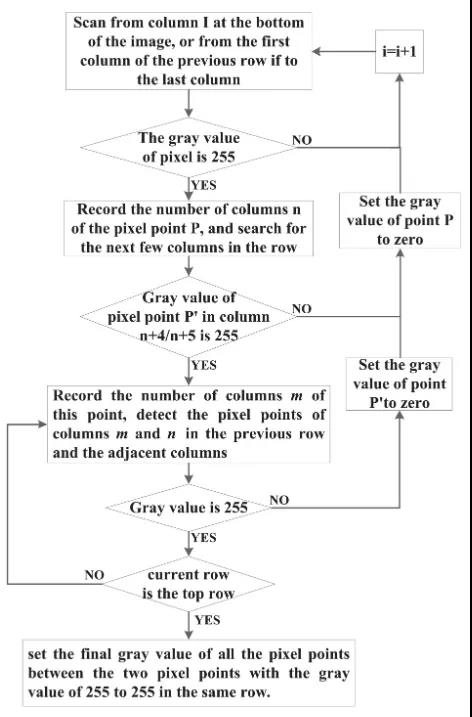
車道線特征點提取的詳細步驟如下:
步驟1:從圖像底部開始逐行掃描二值圖像。如果檢測到某行像素點的灰度值全為0,則繼續掃描上一行像素點,否則轉步驟2。
步驟2:記錄第一個灰度值為255的像素點的列號n,并繼續掃描下一個像素點。若第n列第4或第5個像素點的灰度值仍為255,則記錄該點的列號m,并執行步驟3;否則,將第一個灰度值為255的像素點視為干擾點,將其值設置為零然后繼續掃描,然后重復步驟2。
步驟3:繼續檢測上一行n列和m列像素點的灰度值。若灰度值為255,則重復步驟3;否則,檢測相鄰列像素點的灰度值,如果為255,則重復步驟3;否則,將步驟二中距離為4或5個像素的兩個像素點確定為干擾點,并將其值設置為0。繼續步驟2,從該行的下一個像素開始掃描。
步驟4:掃描完各行各列的像素點后,設置同一行灰度值為255~255的兩個像素點之間的所有像素點的最終灰度值。
上述流程如圖7所示:
下圖顯示了以上這種基于車道線寬度算法逐行掃描后的車道線提取結果。

可以看到,該算法在盡可能減少干擾點數量的情況下提取了足夠的車道線邊緣點,逐行掃描方法基本上成功地從所有像素點中提取出屬于車道線的邊緣點。另外,可以看出,質量較差的車道虛線符合本文設計的提取規則,也可以被很好的提取。
基于RANSAC的特征點曲線擬合
圖像預處理后,多條車道線上存在散點。需要對這些散點進行擬合,找到一條可以包含足夠多散點的曲線,即一條可以包含足夠多散點的曲線。本文采用RANSAC對特征點進行擬合,形成最適合車道線的曲線。有學者在研究中使用canny方法作為比較對象,得到了較差的車道線檢測結果。除了它對Canny算法缺乏改進之外,另一個重要原因是它使用了最小二乘法而不是RANSAC。最小二乘法就是從所有的點中找出最合適的曲線。這種不放棄的方法會導致所有噪聲點都被考慮在內,因此不適合與Canny算法一起使用。RANSAC是一種非確定性算法,它會在一定的概率下產生合理的結果,這允許更多的迭代來增加其概率。操作流程如下:
第一步:假設模型是一個三階曲線方程,隨機選取3個樣本點來擬合模型:
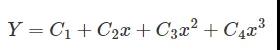
第二步:假設公差范圍為 z,找出距離擬合曲線公差范圍內的點,并統計點數。
第三步:再次隨機選擇3個點,重復第一步到第二步的操作,直至迭代結束。
總之,每次擬合后,在公差范圍內都有相應的數據點。找出滿足設定置信度的數據點數量就是最終的擬合結果。本文通過設置置信度條件來確定最大迭代次數。步驟1-3的迭代次數與模型的異常值比例以及我們需要的置信度有關。可以用以下公式表示:
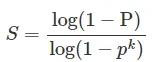
其中 S 是所需測試的最小數量,P是置信水平,p是內點百分比,k是隨機樣本數量。具體的置信水平需要通過反復測試并綜合考慮準確性和實時性來確定。
在上述算法不同場景下進行了驗證,并在原始圖像上標注了最終的車道線,并選取了一些有代表性的截圖如下圖所示。圖(a)為正常光照區域,(b)為光照不均勻區域,(c)為大陰影區域,(d)為線條干擾區域,(e)為高亮度區域。

基于逆透視投影變換的特征點擬合
傳統算法中,通過基于RANSAC算法的貝塞爾曲線擬合算法對邊緣點進行擬合,可以得到識別的車道線。然而這種RANSAC算法擬合是通過直接逐行掃描圖像,利用寬度匹配來確定哪些散點屬于車道線的。該方法沒有考慮攝像頭獲取的圖像中車道線可能不是垂直的情況,圖像中存在一定的角度的傾斜,所以需要逆透視變換或者距離變換,為后續車道線特征點的選擇和提取做好準備。
為了解決以上問題,可以利用逆透視變換算法可以將發生幾何變形的平面圖像變換為無畸變的俯視圖。目前實現逆透視變換的方法主要有兩種:
第一種是通過相機標定方法獲得相機的內參數和外參數,變換公式由內參數矩陣和外參數矩陣根據相機的成像模型,最后通過計算得到逆透視變換后的俯視圖。該方法雖然可以校正相機的畸變,但涉及參數和變量較多,算法復雜,運算時間長。
第二種方法是推導透視原理的幾何關系,利用簡化的逆透視變換公式進行計算,從而得到圖像的俯視圖。這種方法適用于畸變較小的小角度相機。
考慮到現有相機的特點和實時性,從簡化算法和實現功能的角度出發,推薦選擇對第一種逆透視變換方法進行一定程度的簡化。
由于現有的逆透視技術已經比較成熟,本文不再討論其推導過程,整體改造如下:
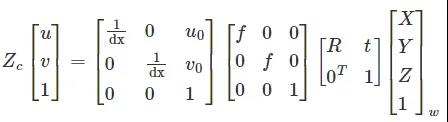
其中旋轉矩陣R是3*3的矩陣,t是偏移量。從后到前,中間三個矩陣分別是相機與世界坐標變換矩陣、投影關系矩陣和像素相平面關系矩陣。
由于智能車的車載攝像頭安裝在車輛內部時通常是固定俯仰角和側傾角的,因此可以簡化為上述類型。如果相機安裝仔細,不相對Z軸旋轉,并考慮到地平線實際上是水平的,道路所在平面取ZW=0,上式可進一步簡化如下:
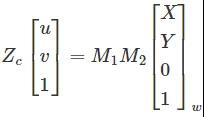
其中,ZC為透視投影系數,M1為相機內參矩陣,由相機內參fx、fy、u0、v0確定;M2是相機的外參矩陣,其中R和T是由相機位置決定的坐標變換矩陣。
根據上述原理,可以找到圖像平面中的點與世界坐標系中的點的一一對應關系,然后將其轉化為鳥瞰圖。
需要說明的是,由于遠處像素數量較少,轉換為鳥瞰圖時需要進行大量的插值和擬合計算。在遠離傳感器的區域進行鳥瞰圖的變換不僅消耗計算能力,而且無法提供清晰的車道線。因此,如果針對低速無人駕駛汽車而言,僅對ROI區域進行變換(對于同一相機,ROI區域的像素坐標固定),最終使車道線的兩條邊平行,使得進一步的分析變得更加容易。逆透視投影變換得到的近距離車道線還是比較精準的還原。而針對高速情況下需要考慮探測到更遠距離的車道線,而視覺感知能識別到的車道線散點往往較少,同時考慮到計算的實時性要求也更高,因此很難做到高速情況下利用單純的逆透視投影變換還原車道線信息。
我們知道后續BEV鳥瞰圖的基礎算法也是這樣多個攝像頭作為圖像源投影到3D空間后進行匹配拼接而得出全景的,可以說這種拼接過程也就是一種簡化版的三維重建。那么,如果是遠距離情況下的散點而言,點數顯然不夠多,投影到3D空間中用于點云重建的點就很有限了,這就意味著很難在其空間中通過拼接重現真實世界場景中的車道線,亦或者重建的車道線質量也無法滿足檢測要求。
當然,有條件的感知算法供應商為了彌補這樣的缺陷往往采用兩種比較典型的方法進行:
1、大量真值系統注入
實際就是一種Mono 3D的真值訓練法。提前通過激光+攝像頭的方式做數據閉環進行全場景采樣,得到了真實環境下的各種車道線采樣場景數據,然后通過人工標注的方式進行場景標注,這樣一套標注值可以提前寫入到真值系統中。當后續運行對應的感知識別算法時,只需要在進行圖像預處理后輸入對應的真值系統做圖像Match就可以很直觀的得出對應的車道線真值了。
當然,1中所提到的方案不是在每個算法供應商都能采用的,其一是這樣的真值系統需要采集大量的環境真值數據,這需要大量的車隊來運行采集過程。且不談是否合規的問題,就是這樣龐大的車隊容量也不是一般公司能夠承受的。那么,此時也有一些追求性價比的算法供應商會采用第二種方法:單V加BEV融合的算法策略。
2、單V加BEV的融合策略
其實,簡單點說就是視覺感知的大融合技術。即考慮到大小眼攝像頭的小眼睛能識別到更遠距離的車道信息,大眼睛能識別到更寬的車道信息,先各自分別跑各自的神經網絡算法,得到對應的環境感知輸出。其次,該大小眼仍然參與整車全視角下的BEV構建,通過上述所提到的逆透視投影變換得到對應的BEV鳥瞰圖。最后,將前兩者的感知模塊通過變換到同一個坐標系下進行融合生成對應的三維感知結果將更加準確的還原實際場景。
這里需要注意的是,考慮到計算資源和效率,由于智能汽車更關注自車道前方的車道線信息,因此,對于單V識別,考慮前視大小眼就足夠彌補BEV在遠距離感知中的缺陷了。當然不差錢的Tier1或主機廠,如果選擇了較大算力平臺的域控,也可以分別將側視和后視進行單獨深度學習生成對應的感知結果。
總結
本文接續前文介紹了利用車道寬度這一顯著特征來提取滿足該特征的邊緣點,最終利用RANSAC特征點擬合的方法得到識別的車道線。多個代表性場景的實驗結果表明,該方法對復雜光照條件具有較強的適應性,能夠在高反光、暗影、照度不均等區域識別視場內的路徑像素。因此,在正常道路和特殊環境下基本不會出現識別失敗的情況。
轉自焉知汽車
